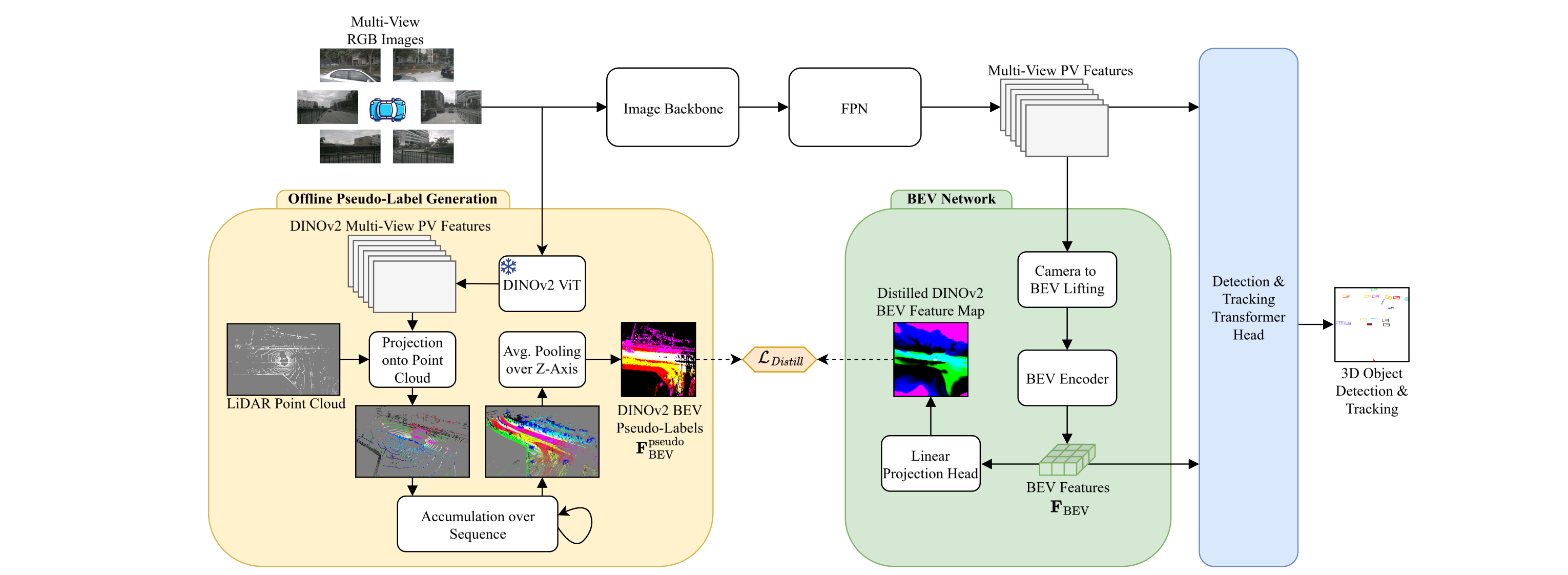
Camera-based 3D object detection and tracking are essential for perception in autonomous driving. Current state-of-the-art approaches often rely exclusively on either perspective-view (PV) or bird’s-eye-view (BEV) features, limiting their ability to leverage both fine-grained object details and spatially structured scene representations. In this work, we propose DualViewDistill, a hybrid detection and tracking framework that incorporates both PV and BEV camera image features to leverage their complementary strengths. Our approach introduces BEV maps guided by foundation models, leveraging descriptive DINOv2 features that are distilled into BEV representations through a novel distillation process. By integrating PV features with BEV maps enriched with semantic and geometric features from DINOv2, our model leverages this hybrid representation via deformable aggregation to enhance 3D object detection and tracking. Extensive experiments on the nuScenes and Argoverse 2 benchmarks demonstrate that DualViewDistill achieves state-of-the-art performance. The results showcase the potential of foundation model BEV maps to enable more reliable perception for autonomous driving.